Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-update-training-api-26.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
 Instructor は、LLM から JSON などの構造化データを簡単に取得できるようにする軽量なライブラリです。
Instructor は、LLM から JSON などの構造化データを簡単に取得できるようにする軽量なライブラリです。
トレーシング
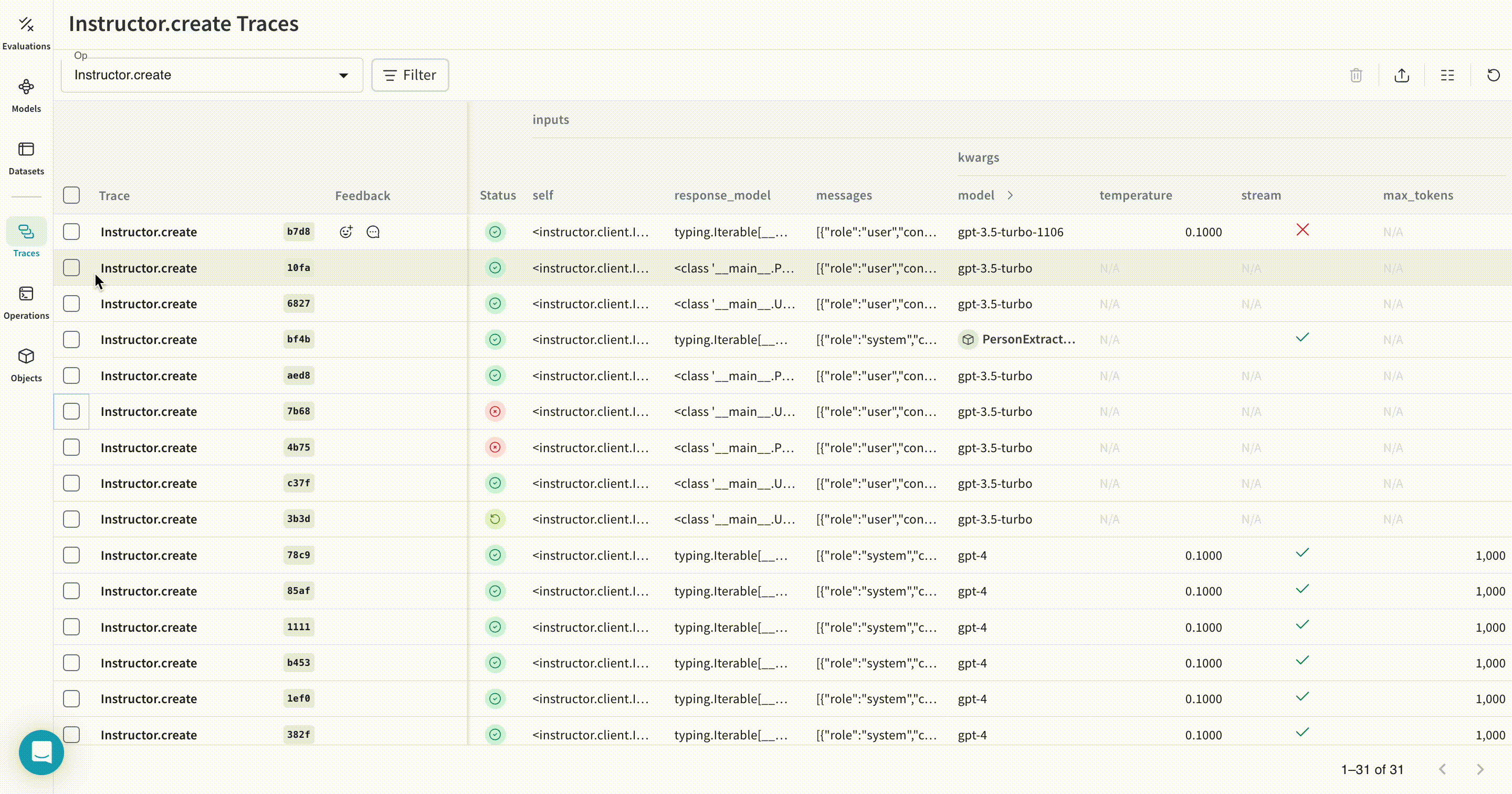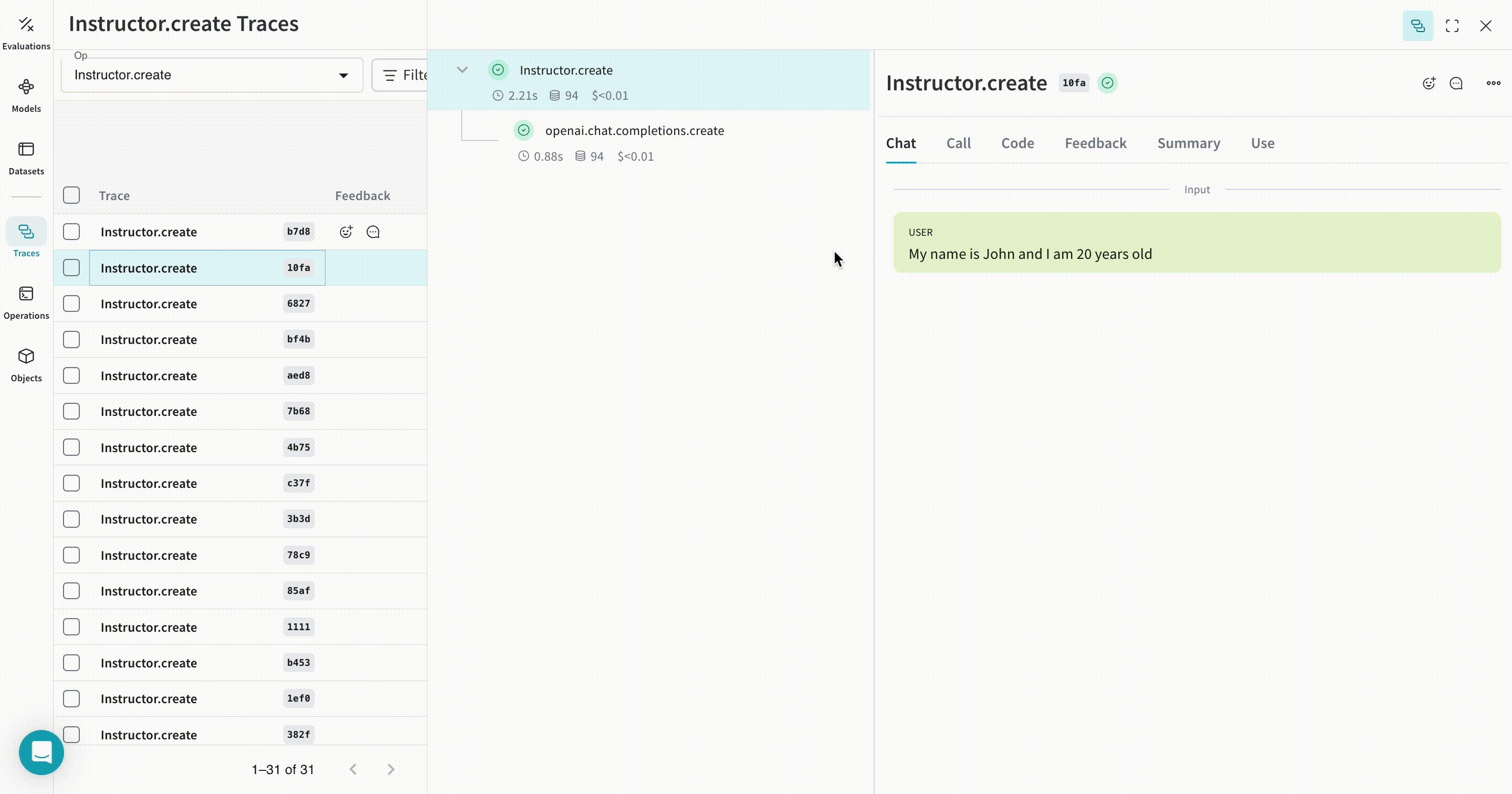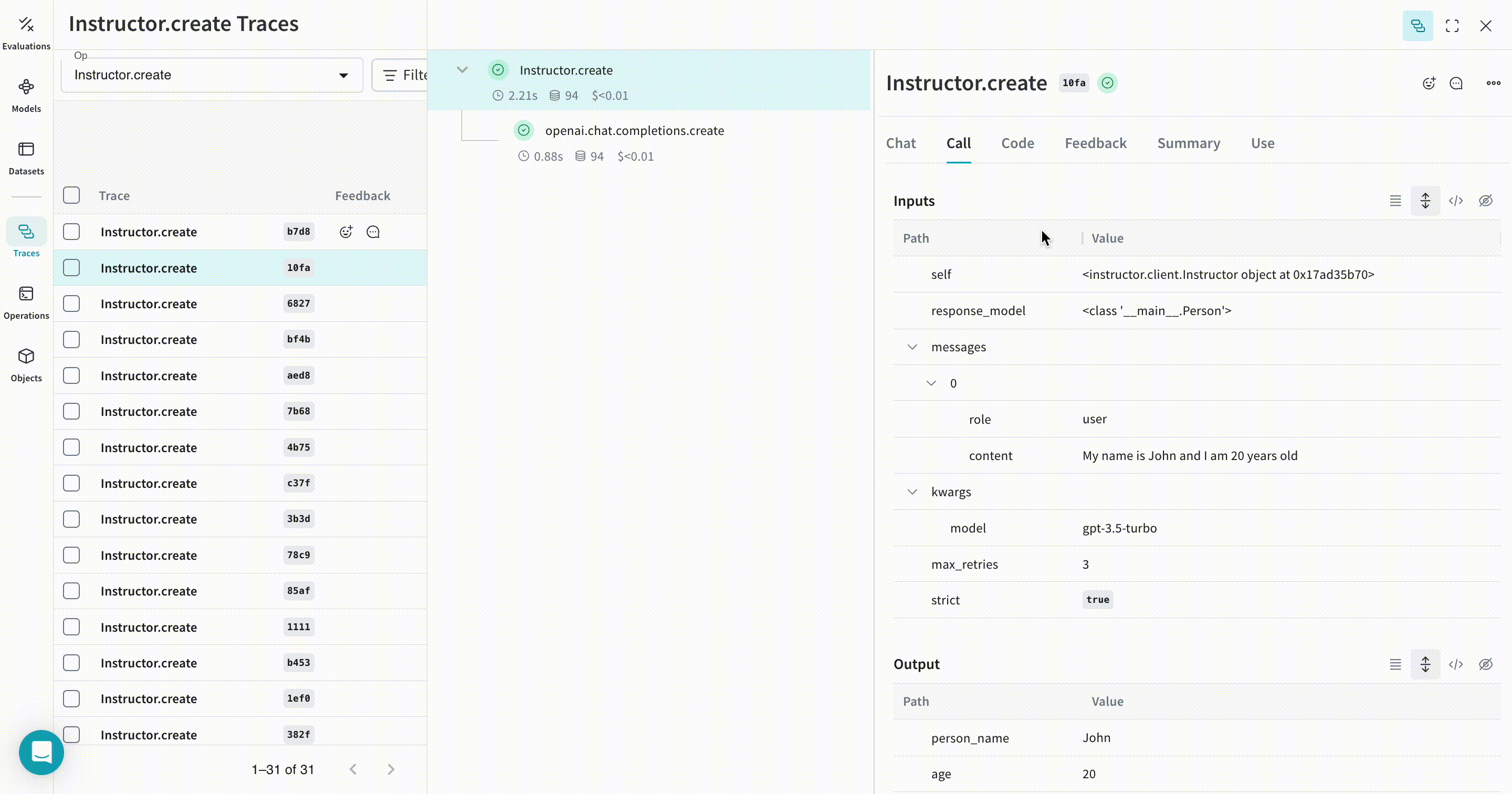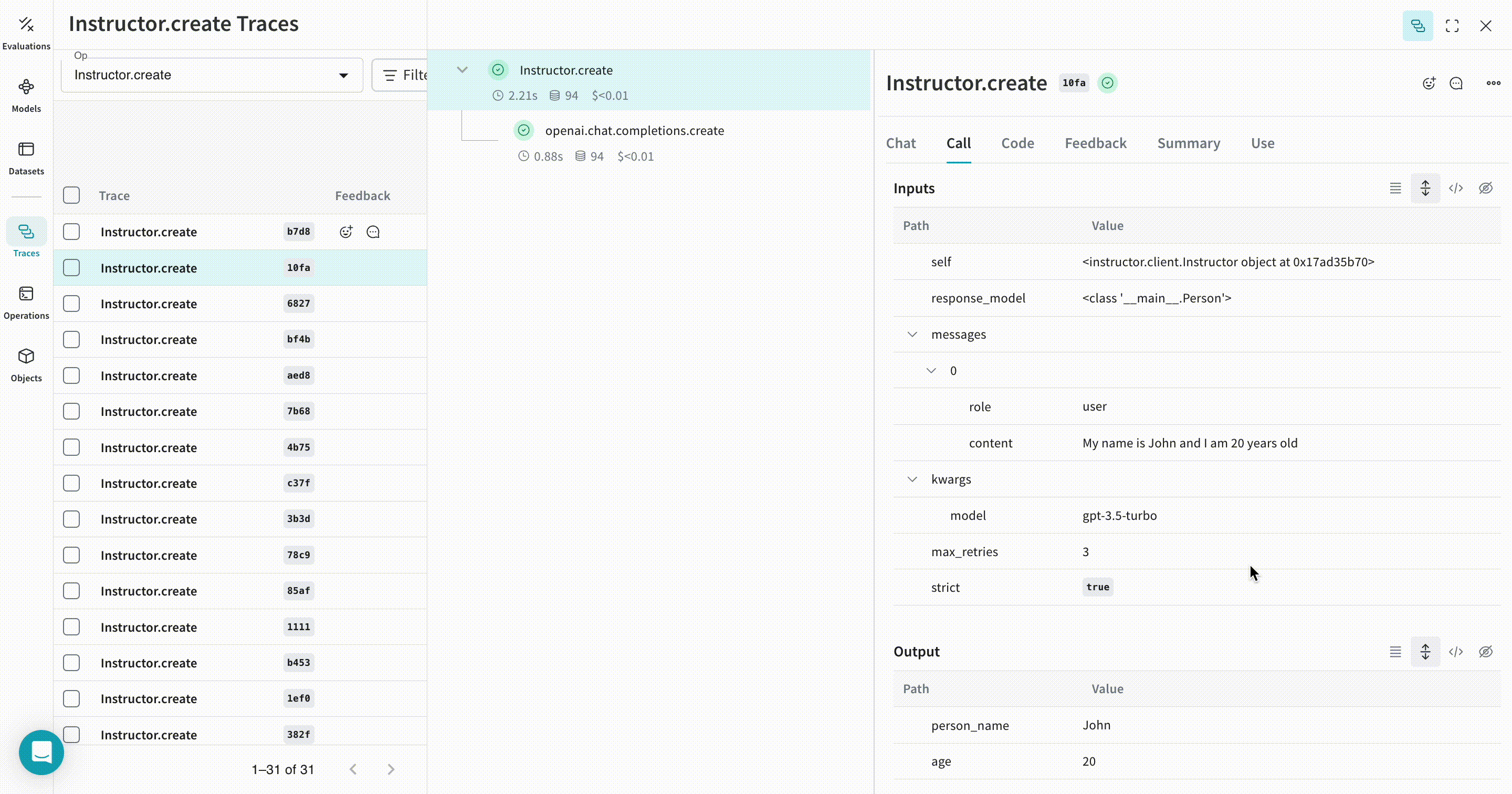
開発中および プロダクション の両方において、言語モデル アプリケーション の トレース を中央の場所に保存することは重要です。これらの トレース は、デバッグや、アプリケーション を改善するのに役立つ データセット として有用です。
Weave は Instructor の トレース を自動的にキャプチャします。追跡を開始するには、weave.init(project_name="<YOUR-WANDB-PROJECT-NAME>") を呼び出し、通常通りライブラリを使用してください。
import instructor
import weave
from pydantic import BaseModel
from openai import OpenAI
# 期待する出力構造を定義
class UserInfo(BaseModel):
user_name: str
age: int
# Weave を初期化
weave.init(project_name="instructor-test")
# OpenAI クライアントにパッチを適用
client = instructor.from_openai(OpenAI())
# 自然言語から構造化データを抽出
user_info = client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=UserInfo,
messages=[{"role": "user", "content": "John Doe is 30 years old."}],
)
 |
|---|
| Weave は、Instructor を使用して行われたすべての LLM 呼び出しを追跡し、ログを記録します。Weave の Web インターフェースで トレース を確認できます。 |
独自の op を追跡する
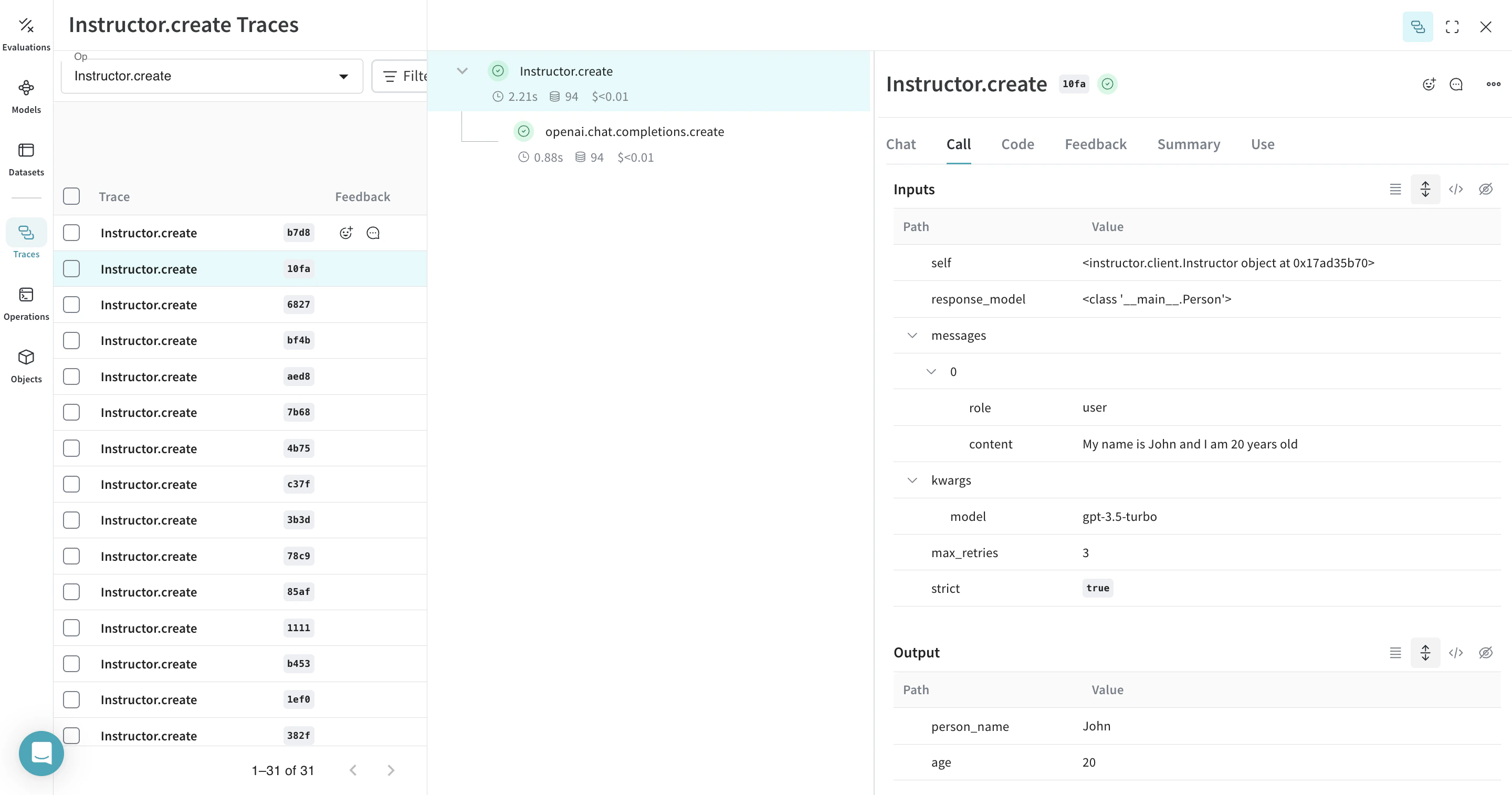
関数を @weave.op でラップすると、入力、出力、および アプリケーション ロジックのキャプチャが開始され、データが アプリケーション 内をどのように流れるかをデバッグできるようになります。op を深くネストして、追跡したい関数の ツリー を構築できます。これにより、実験 中に git にコミットされていないアドホックな詳細をキャプチャするために、コード の バージョン管理 も自動的に開始されます。
@weave.op でデコレートされた関数を作成するだけです。
以下の例では、extract_person という関数があり、これが @weave.op でラップされたメトリクス関数です。これにより、OpenAI のチャット完了呼び出しなど、中間ステップがどのように行われているかを確認できます。
import instructor
import weave
from openai import OpenAI
from pydantic import BaseModel
# 期待する出力構造を定義
class Person(BaseModel):
person_name: str
age: int
# Weave を初期化
weave.init(project_name="instructor-test")
# OpenAI クライアントにパッチを適用
lm_client = instructor.from_openai(OpenAI())
# 自然言語から構造化データを抽出
@weave.op()
def extract_person(text: str) -> Person:
return lm_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": text},
],
response_model=Person,
)
person = extract_person("My name is John and I am 20 years old")
 |
|---|
extract_person 関数を @weave.op でデコレートすることで、その入力、出力、および関数内で行われるすべての内部 LM 呼び出しが トレース されます。Weave はまた、Instructor によって生成された構造化 オブジェクト を自動的に追跡し、バージョン管理 します。 |
実験 を容易にするために Model を作成する
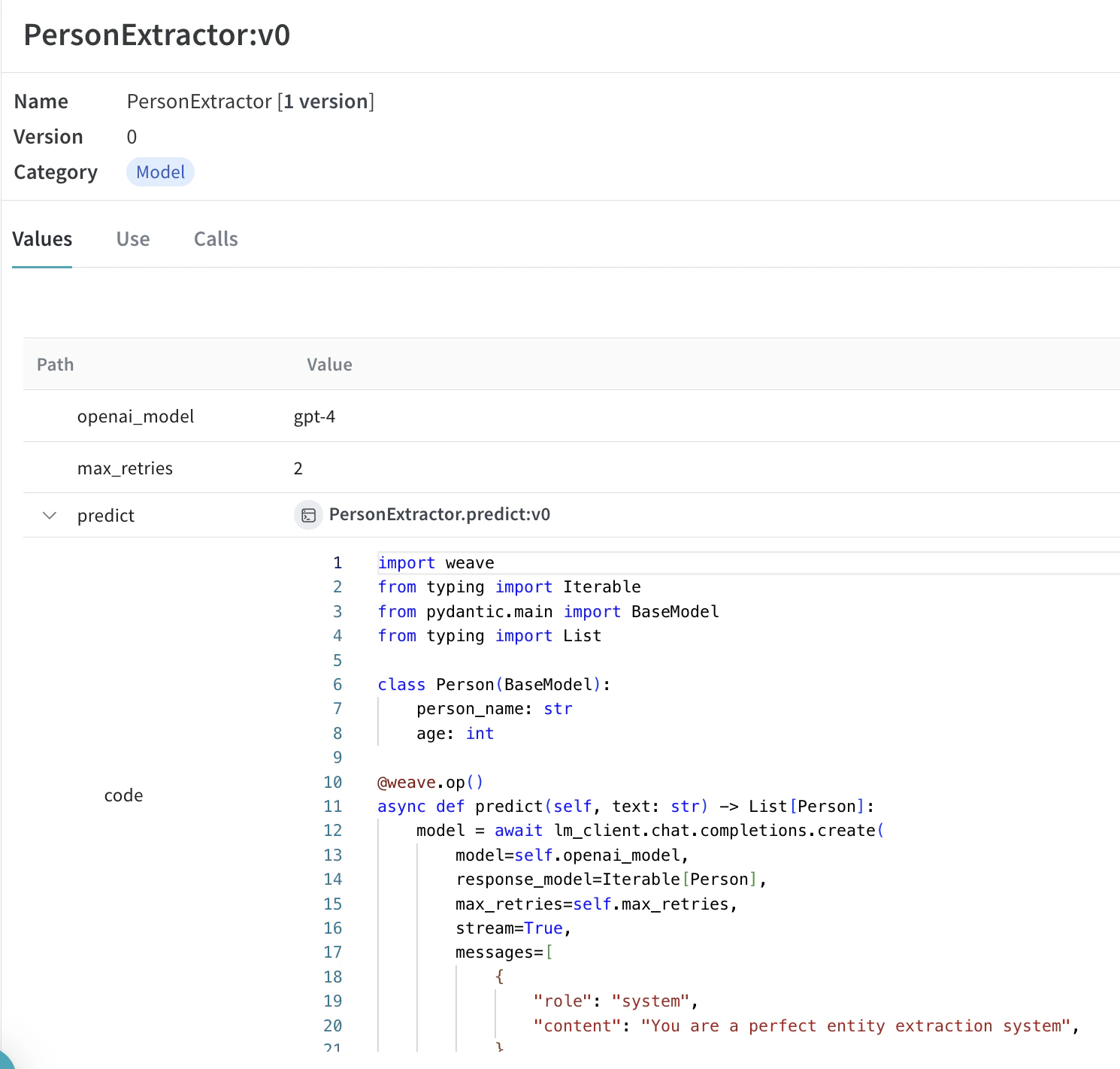
多くの動的な要素がある場合、実験 の整理は困難になります。Model クラスを使用すると、システムプロンプトや使用している モデル など、アプリケーション の 実験 的な詳細をキャプチャして整理できます。これにより、アプリケーション の異なるイテレーションを整理し、比較するのに役立ちます。
コード の バージョン管理 や入力/出力のキャプチャに加えて、Model は アプリケーション の 振る舞い を制御する構造化された パラメータ をキャプチャし、どの パラメータ が最も効果的であったかを簡単に見つけられるようにします。また、Weave の Models は serve(以下を参照)や Evaluations と併用することもできます。
以下の例では、PersonExtractor を使って 実験 できます。これらのいずれかを変更するたびに、PersonExtractor の新しい バージョン が作成されます。
import asyncio
from typing import List, Iterable
import instructor
import weave
from openai import AsyncOpenAI
from pydantic import BaseModel
# 期待する出力構造を定義
class Person(BaseModel):
person_name: str
age: int
# Weave を初期化
weave.init(project_name="instructor-test")
# OpenAI クライアントにパッチを適用
lm_client = instructor.from_openai(AsyncOpenAI())
class PersonExtractor(weave.Model):
openai_model: str
max_retries: int
@weave.op()
async def predict(self, text: str) -> List[Person]:
model = await lm_client.chat.completions.create(
model=self.openai_model,
response_model=Iterable[Person],
max_retries=self.max_retries,
stream=True,
messages=[
{
"role": "system",
"content": "You are a perfect entity extraction system",
},
{
"role": "user",
"content": f"Extract `{text}`",
},
],
)
return [m async for m in model]
model = PersonExtractor(openai_model="gpt-4", max_retries=2)
asyncio.run(model.predict("John is 30 years old"))
 |
|---|
Model を使用した呼び出しの トレース と バージョン管理 |
Weave Model をサービングする
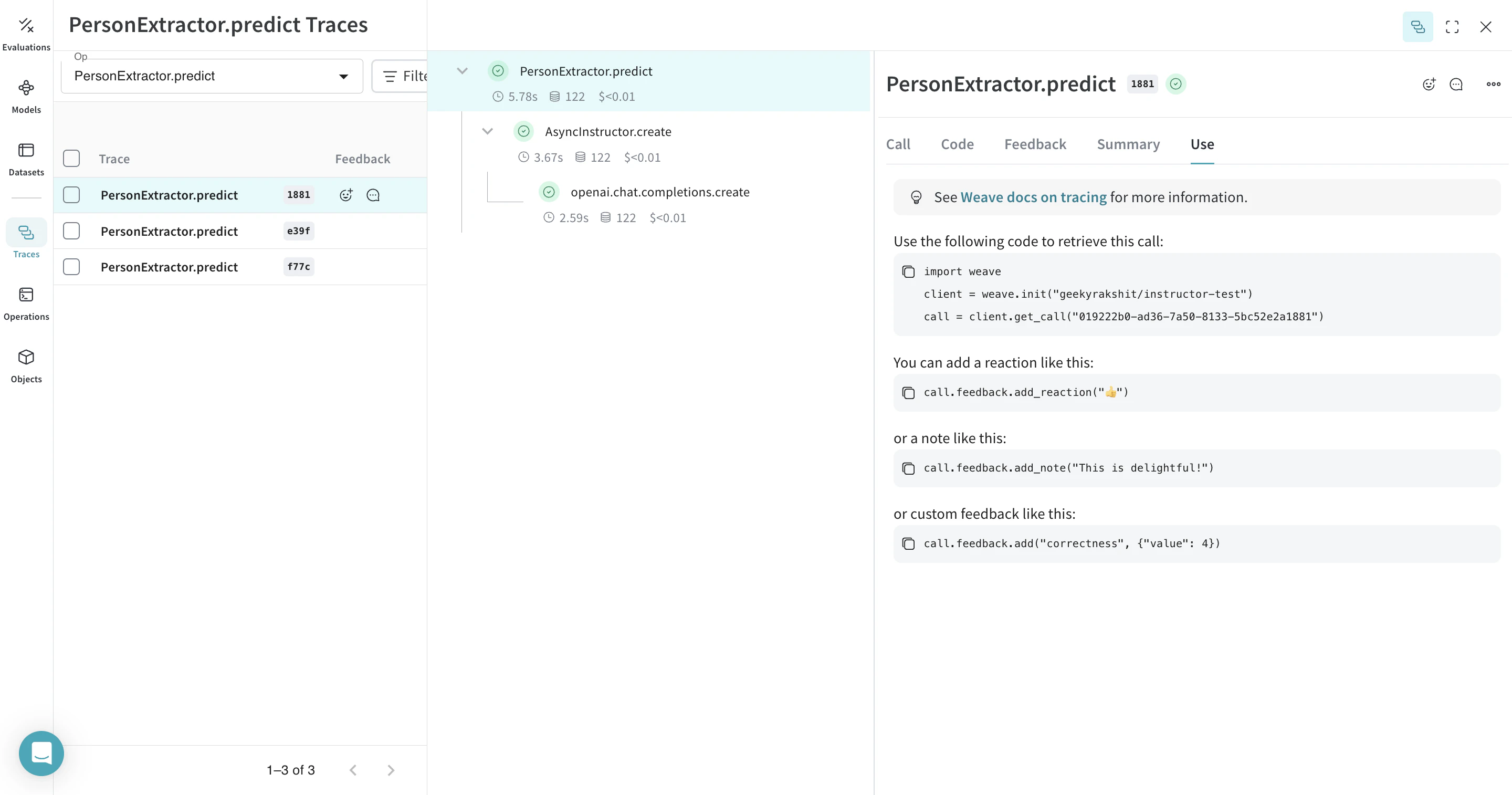
weave.Model オブジェクト の Weave リファレンスを指定することで、FastAPI サーバーを起動して serve することができます。
 |
|---|
任意の weave.Model の Weave リファレンスは、モデル に移動して UI からコピーすることで確認できます。 |
weave serve weave://your_entity/project-name/YourModel:<hash>