インタラクティブな Queue monitoring dashboard を使用すると、 Launch のキューが混雑しているかアイドル状態かを確認したり、実行中のワークロードを可視化したり、非効率なジョブを特定したりできます。Launch キューダッシュボードは、計算ハードウェアや クラウド リソースを効果的に活用できているかを判断する際に特に役立ちます。 より詳細な分析を行うために、このページからは W&B の 実験管理 Workspace や、Datadog、NVIDIA Base Command、クラウド コンソールなどの外部インフラ監視プロバイダーへのリンクが提供されています。Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-update-training-api-26.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Queue monitoring dashboard は、現在 W&B Multi-tenant Cloud デプロイメントオプションでのみ利用可能です。
ダッシュボードとプロット
Monitor タブを使用して、過去 7 日間に発生したキューのアクティビティを表示します。左側のパネルを使用して、時間範囲、グループ化、およびフィルターを制御します。 ダッシュボードには、パフォーマンスと効率に関する よくある質問 に答えるための多数のプロットが含まれています。以下のセクションでは、キューダッシュボードの UI 要素について説明します。Job status
Job status プロットは、各時間間隔で実行中、保留中、キュー投入済み、または完了したジョブの数を示します。Job status プロットを使用して、キューのアイドル期間を特定します。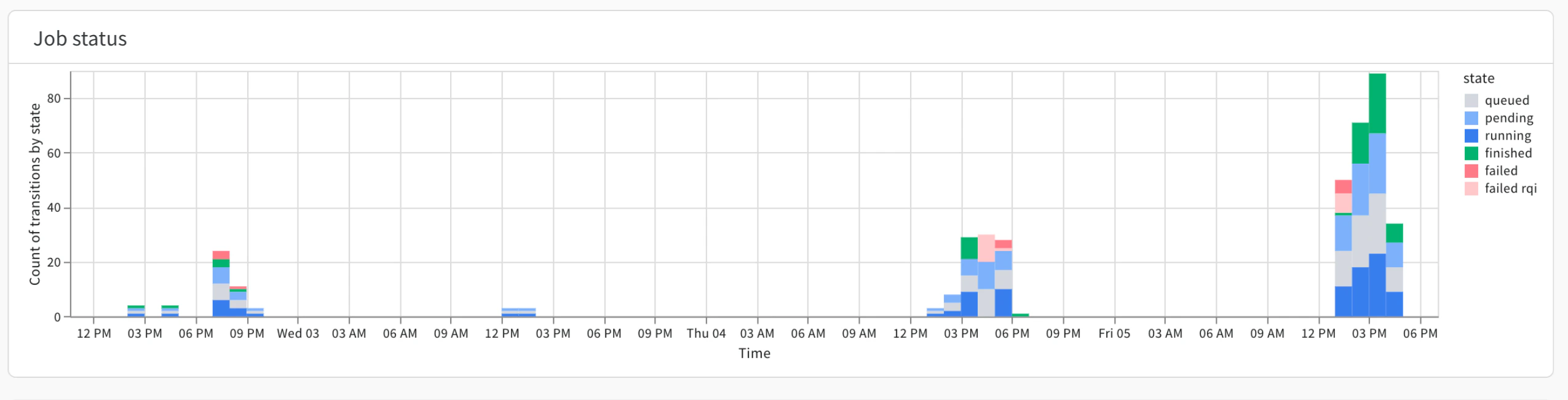
Queued のアイテムは、ワークロードを他のキューに移動させる機会を示している可能性があります。失敗の急増は、Launch ジョブのセットアップでサポートが必要な Users を特定するのに役立ちます。Queued time
Queued time プロットは、特定の期間において Launch ジョブがキューに留まっていた時間(秒単位)を示します。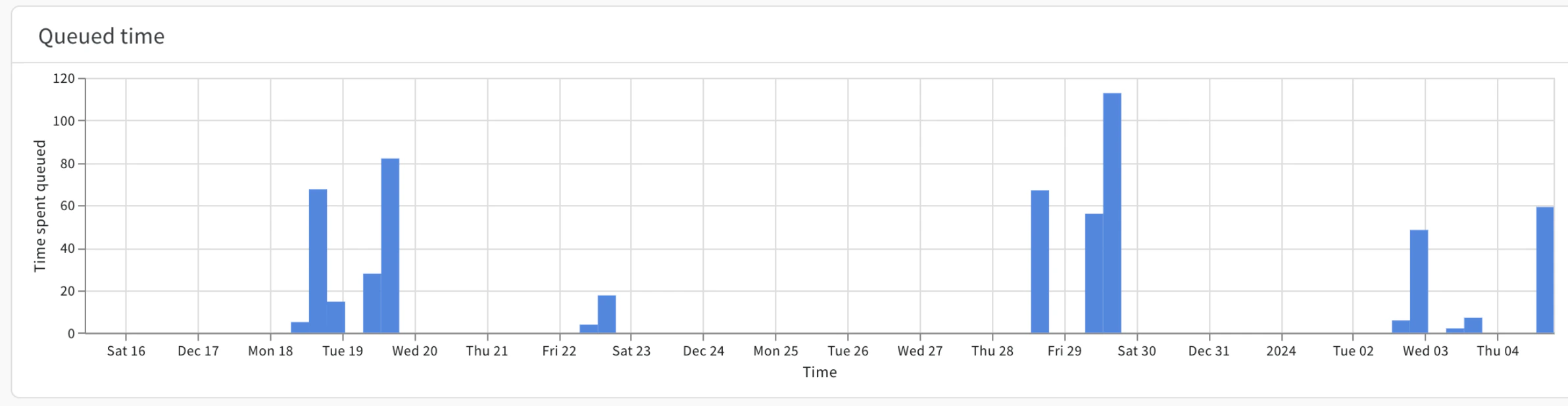
Queued time プロットを使用して、長い待ち時間の影響を受けている Users を特定します。
Grouping コントロールを使用して、各ジョブの色をカスタマイズできます。
これは、どの Users やジョブがキュー容量不足の影響を強く受けているかを特定するのに特に役立ちます。
Job runs
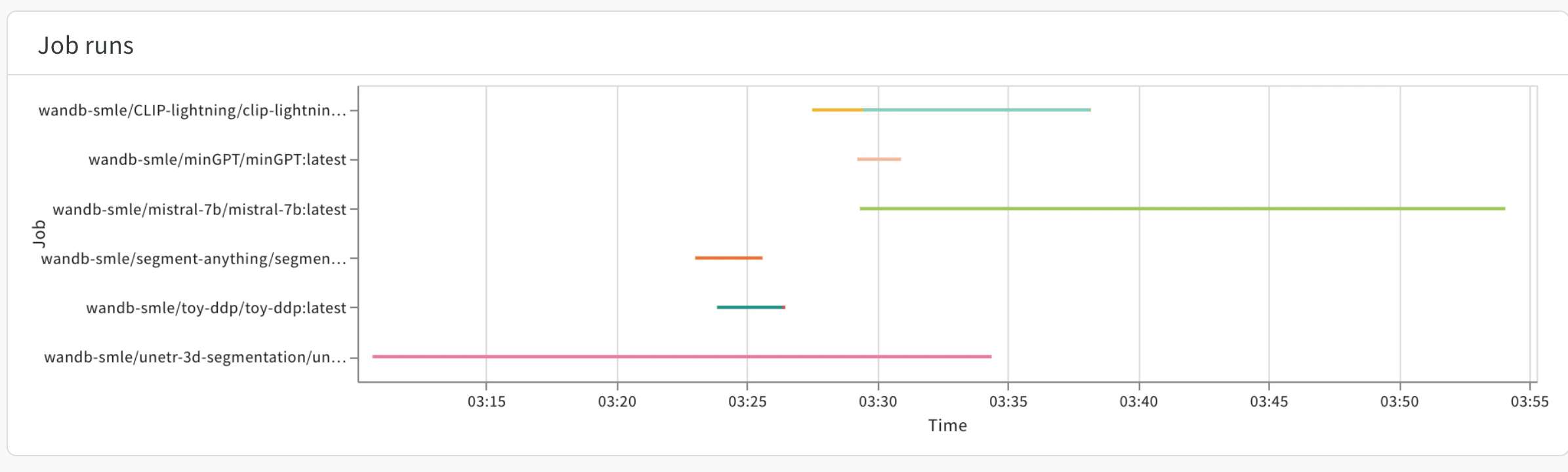
CPU および GPU の使用率
GPU use by a job、CPU use by a job、GPU memory by job、および System memory by job を使用して、Launch ジョブの効率を確認します。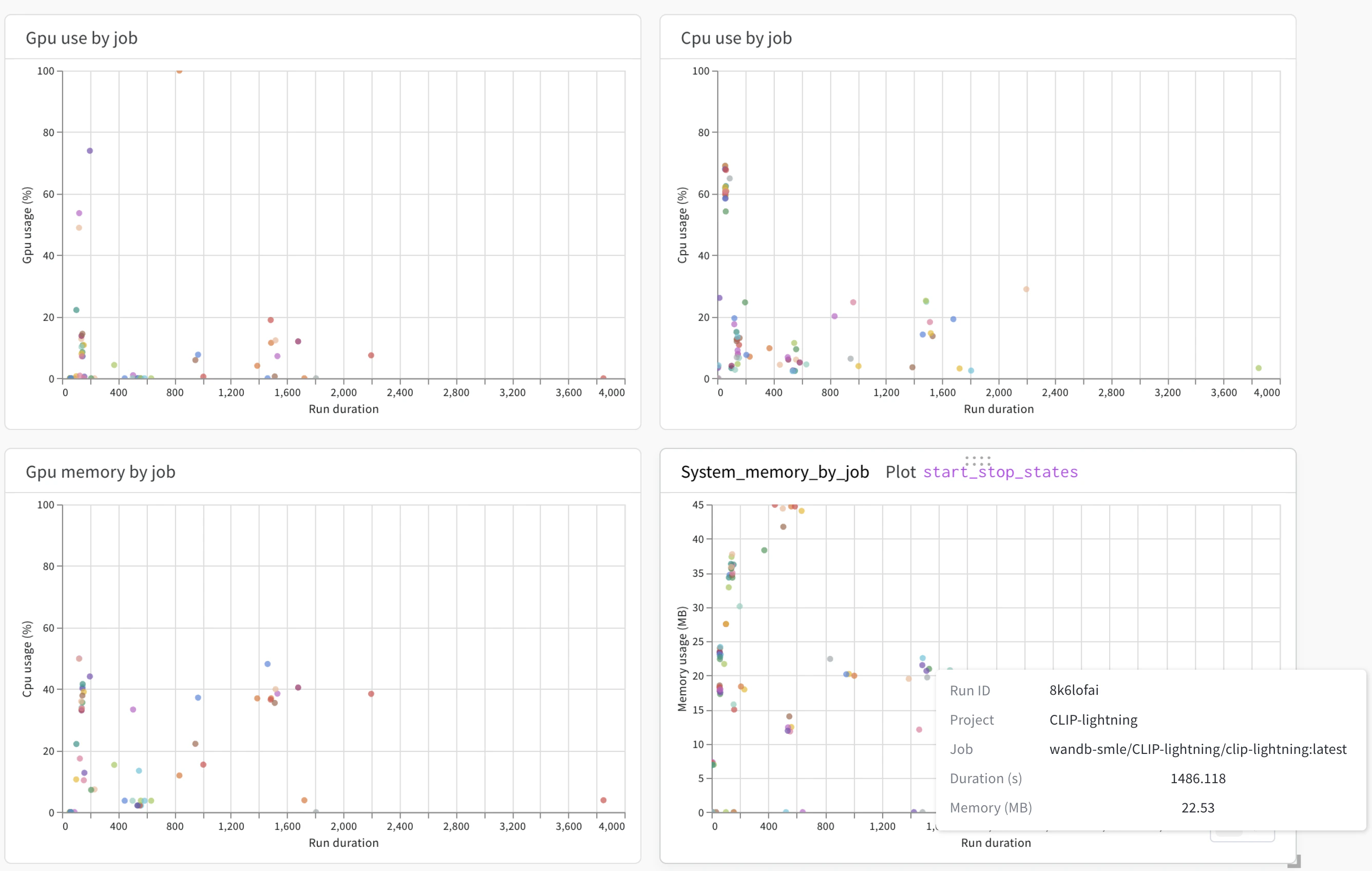
Errors
Errors パネルは、特定の Launch キューで発生したエラーを表示します。具体的には、エラーが発生したタイムスタンプ、エラーの発生元となった Launch ジョブの名前、および生成されたエラーメッセージが表示されます。デフォルトでは、エラーは新しい順に並べられています。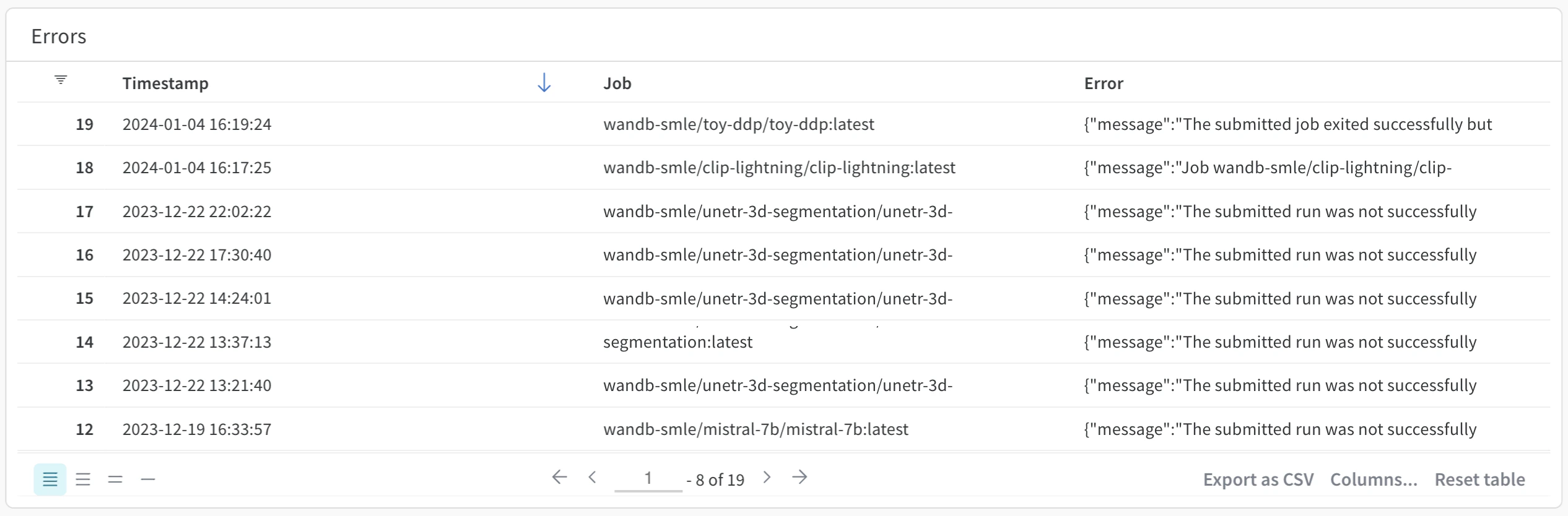
外部リンク
キューの可観測性ダッシュボードのビューはすべてのキュータイプで一貫していますが、多くの場合、環境固有のモニターに直接ジャンプできると便利です。これを実現するには、キューの可観測性ダッシュボードから直接コンソールへのリンクを追加します。 ページの下部にあるManage Links をクリックしてパネルを開きます。目的のページのフル URL を追加し、次にラベルを追加します。追加したリンクは External Links セクションに表示されます。