このチュートリアルでは、PyTorch と MNIST データを使用して、トレーニングの過程でモデルの予測を追跡、可視化、比較する方法について説明します。 以下の方法を学ぶことができます:Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-update-training-api-26.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
- モデルのトレーニングまたは評価中に、メトリクス、画像、テキストなどを
wandb.Table()にログを記録する - これらのテーブルを表示、ソート、フィルタリング、グループ化、結合、対話的なクエリ、探索する
- モデルの予測や結果を、特定の画像、ハイパーパラメーター/モデルバージョン、またはタイムステップにわたって動的に比較する
例
特定の画像の予測スコアを比較する
ライブサンプル:トレーニングの 1 エポック後と 5 エポック後の予測を比較する →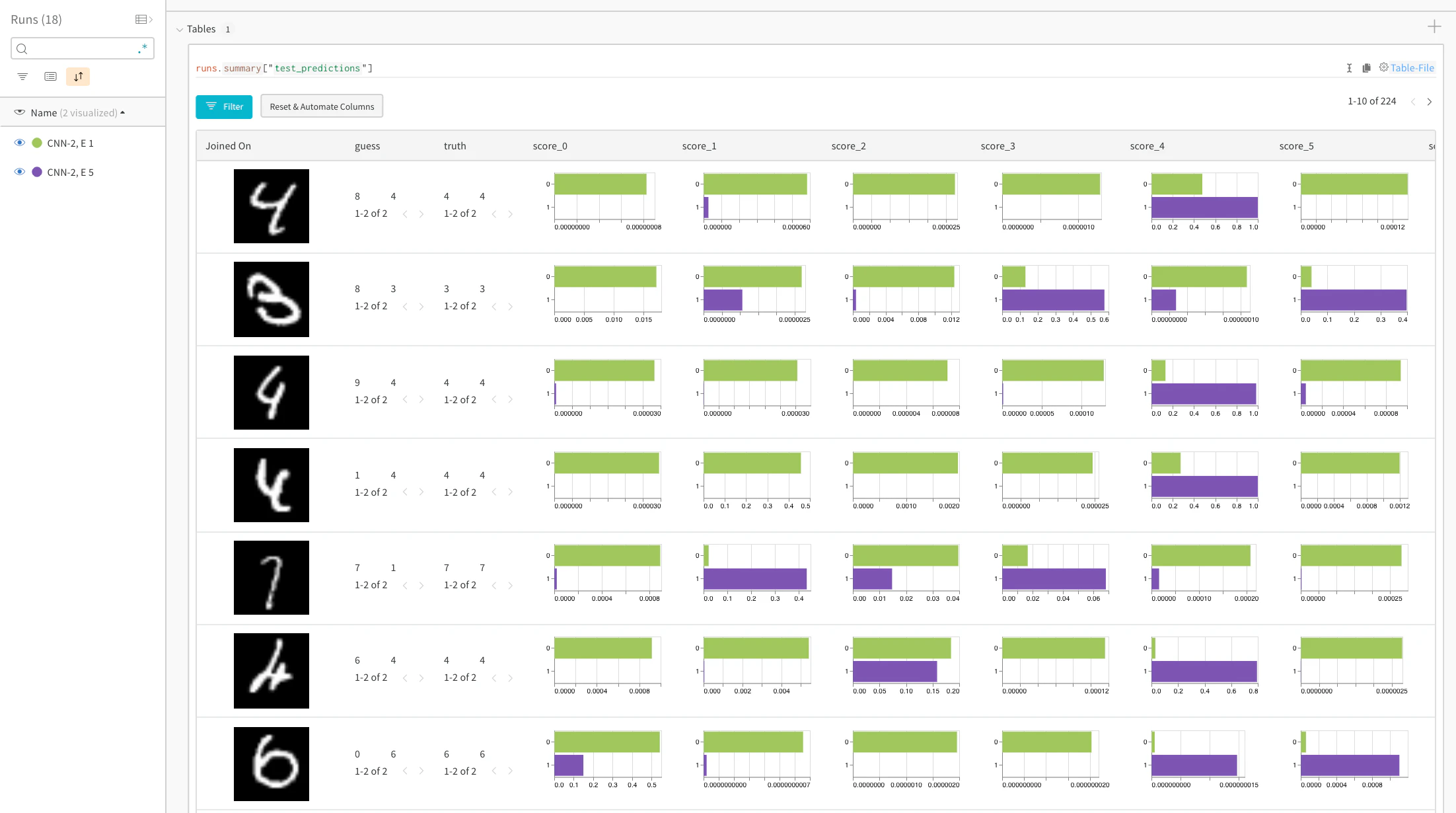
時間経過による主なエラーに注目する
ライブサンプル → テストデータ全体で誤った予測を確認します(“guess” != “truth” の行でフィルタリング)。トレーニング 1 エポック後には 229 件の誤予測がありますが、5 エポック後には 98 件に減少していることがわかります。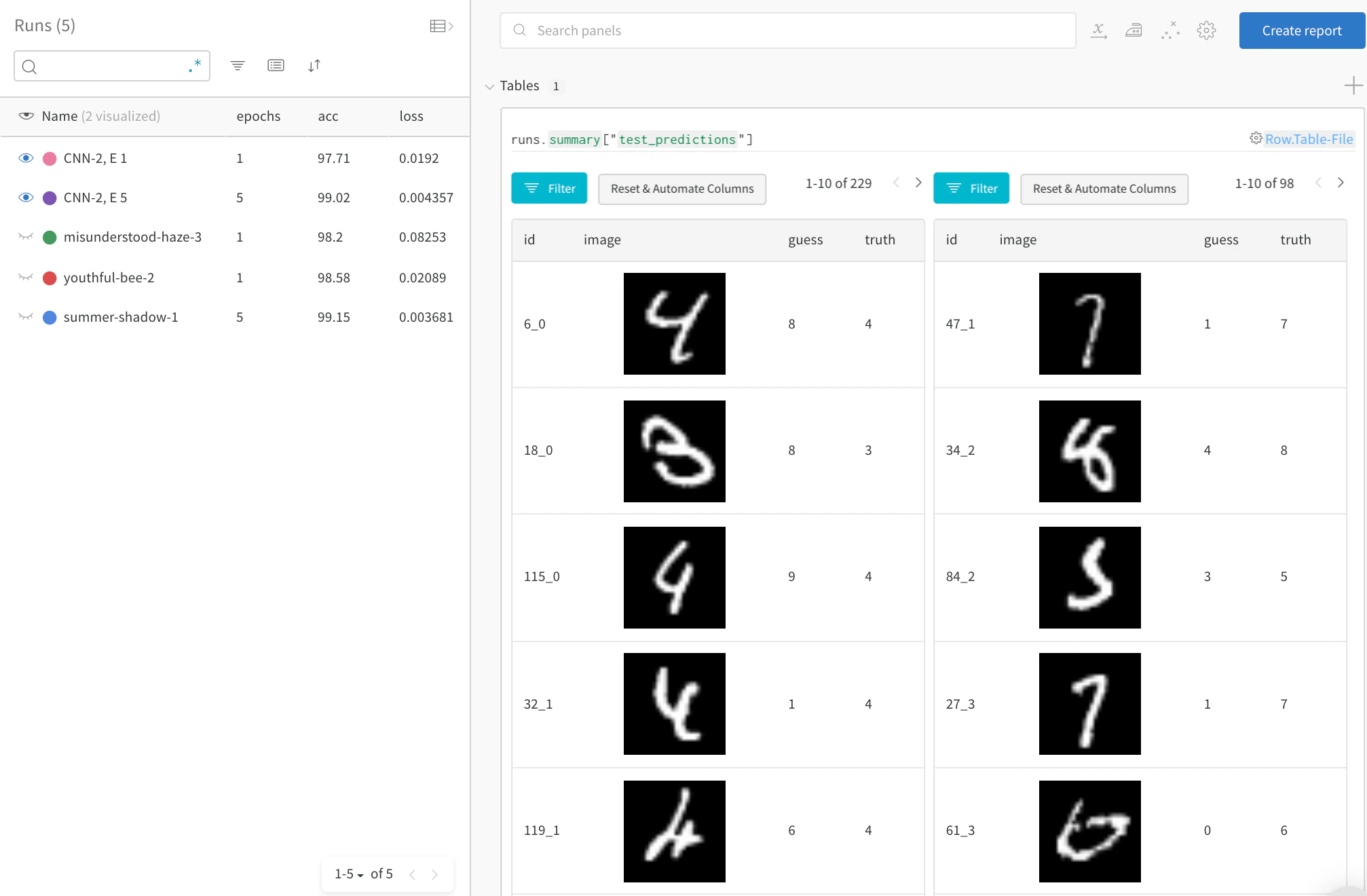
モデルのパフォーマンスを比較しパターンを見つける
ライブサンプルで詳細を確認する → 正解を除外してから予測値(guess)でグループ化し、誤分類された画像の例と、それに対応する正解ラベル(true labels)の分布を 2 つのモデルで並べて確認します。左側はレイヤーサイズと学習率を 2 倍にしたモデルバリアントで、右側はベースラインです。ベースラインの方が、予測された各クラスにおいてわずかにミスが多いことがわかります。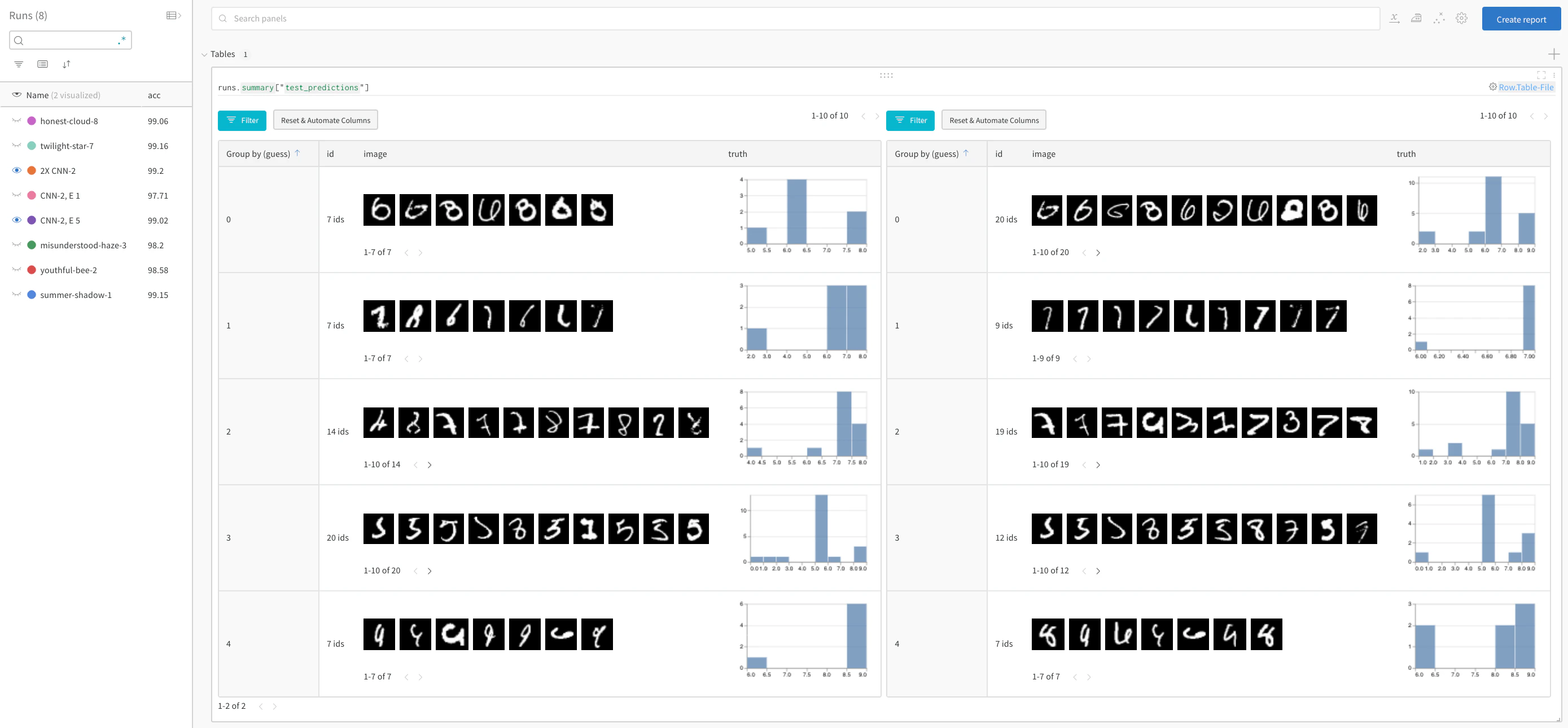
サインアップまたはログイン
W&B に サインアップまたはログイン して、ブラウザで実験をインタラクティブに確認しましょう。 この例では、便利なホスト環境として Google Colab を使用していますが、独自のトレーニングスクリプトをどこからでも実行し、W&B の実験管理ツールでメトリクスを可視化することができます。0. セットアップ
依存関係のインストール、MNIST のダウンロード、および PyTorch を使用したトレーニング用とテスト用のデータセットの作成を行います。1. モデルとトレーニングスケジュールの定義
- 実行するエポック数を設定します。各エポックはトレーニングステップと検証(テスト)ステップで構成されます。オプションで、テストステップごとにログを記録するデータ量を設定します。ここではデモを簡略化するため、可視化するバッチ数とバッチあたりの画像数を少なく設定しています。
- シンプルな畳み込みニューラルネットワークを定義します(pytorch-tutorial のコードを参考にしています)。
- PyTorch を使用してトレーニングセットとテストセットを読み込みます。
2. トレーニングの実行とテスト予測のログ記録
各エポックで、トレーニングステップとテストステップを実行します。各テストステップでは、テスト予測を保存するためのwandb.Table() を作成します。これらはブラウザ上で可視化、動的なクエリ、並べて比較することが可能です。