W&B LaunchをMinikubeクラスターにセットアップし、GPU のワークロードをスケジュールして実行できるようにします。Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-update-training-api-26.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
このチュートリアルは、複数のGPUを搭載したマシンへの直接アクセスがあるユーザーを対象としています。このチュートリアルは、クラウドマシンをレンタルしているユーザーには意図されていません。クラウドマシン上でminikubeクラスターをセットアップしたい場合、W&Bはクラウドプロバイダーを使用したGPU対応のKubernetesクラスターを作成することを推奨します。たとえば、AWS、GCP、Azure、Coreweave、その他のクラウドプロバイダーには、GPU対応のKubernetesクラスターを作成するためのツールがあります。単一のGPUを搭載したマシンでGPUをスケジュールするためにminikubeクラスターをセットアップしたい場合、W&BはLaunch Dockerキューを使用することを推奨します。このチュートリアルを楽しくフォローすることはできますが、GPUのスケジューリングはあまり役に立たないでしょう。
背景
Nvidia コンテナツールキットのおかげで、DockerでGPUを有効にしたワークフローを簡単に実行できるようになりました。制限の一つに、ボリュームによるGPUのスケジューリングのネイティブなサポートがない点があります。docker run コマンドでGPUを使用したい場合は、特定のGPUをIDでリクエストするか、存在するすべてのGPUをリクエストする必要がありますが、これは多くの分散GPUを有効にしたワークロードを非現実的にします。Kubernetesはボリュームリクエストによるスケジューリングをサポートしていますが、GPUスケジューリングを備えたローカルKubernetesクラスターのセットアップには、最近までかなりの時間と労力がかかっていました。Minikubeは、シングルノードKubernetesクラスターを実行するための最も人気のあるツールの1つであり、最近 GPUスケジューリングのサポート をリリースしました 🎉 このチュートリアルでは、マルチGPUマシンにMinikubeクラスターを作成し、W&B Launchを使用してクラスターに並行して安定的な拡散推論ジョブを起動します 🚀
前提条件
始める前に、次のものが必要です:- W&Bアカウント。
- 以下がインストールされているLinuxマシン:
- Docker runtime
- 使用したいGPU用のドライバ
- Nvidiaコンテナツールキット
このチュートリアルをテストし作成するために、4 NVIDIA Tesla T4 GPUを接続した
n1-standard-16 Google Cloud Compute Engineインスタンスを使用しました。Launchジョブ用のキューを作成
最初に、launchジョブ用のlaunchキューを作成します。- wandb.ai/launch(またはプライベートW&Bサーバーを使用している場合は
<your-wandb-url>/launch)に移動します。 - 画面の右上隅にある青い Create a queue ボタンをクリックします。キュー作成のドロワーが画面の右側からスライドアウトします。
- エンティティを選択し、名前を入力し、キューのタイプとして Kubernetes を選択します。
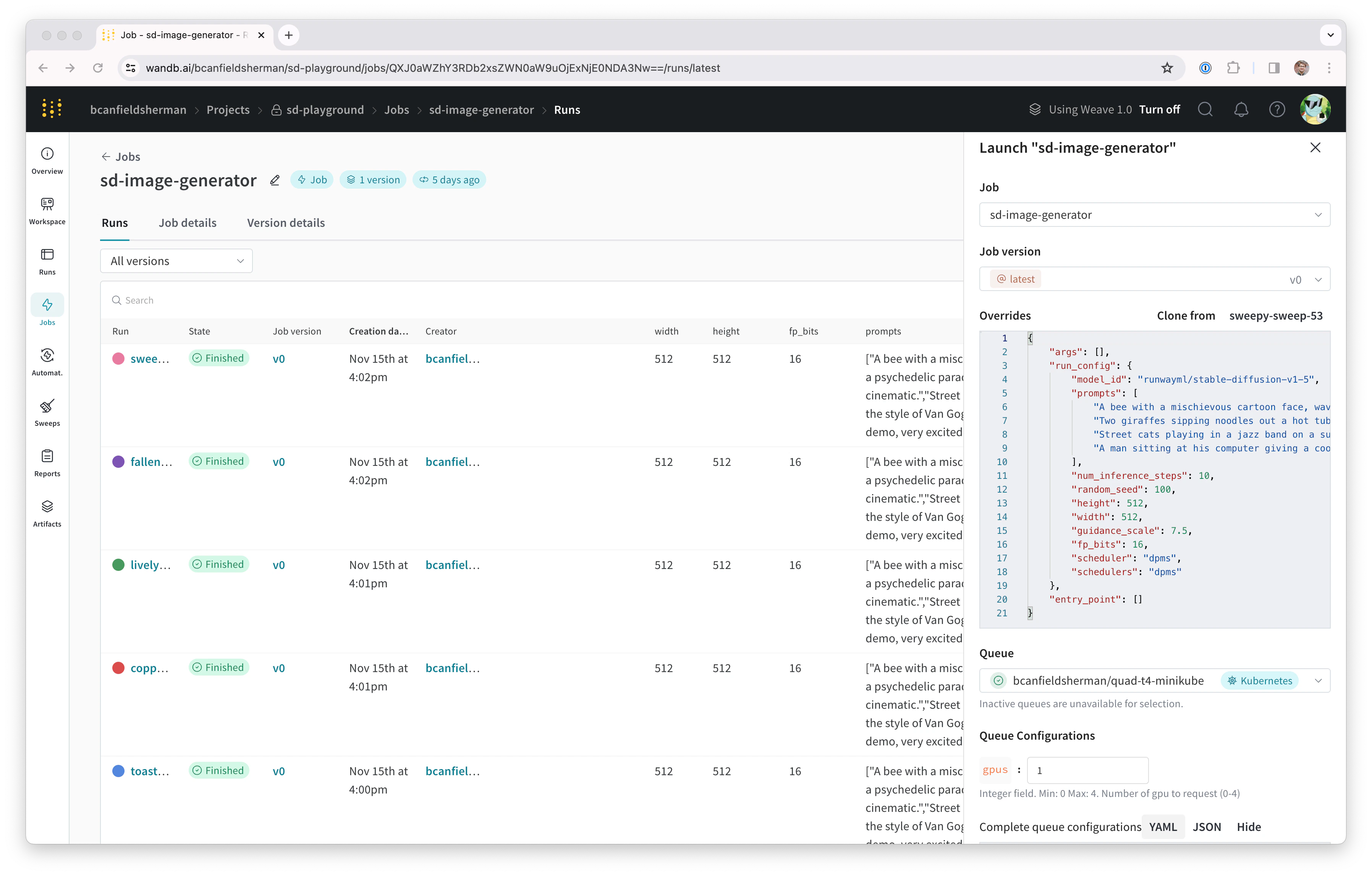
- ドロワーの Config セクションには、launchキュー用のKubernetesジョブ仕様を入力します。このキューから起動されたrunは、このジョブ仕様を使用して作成されるため、必要に応じてジョブをカスタマイズするためにこの設定を変更できます。このチュートリアルでは、下記のサンプル設定をキューの設定にYAMLまたはJSONとしてコピー&ペーストできます:
- YAML
- JSON
${image_uri} と {{gpus}} 文字列は、キュー設定で使用できる2種類の変数テンプレートの例です。${image_uri} テンプレートは、エージェントが起動するジョブの画像URIに置き換えられます。{{gpus}} テンプレートは、ジョブを送信する際にlaunch UI、CLI、またはSDKからオーバーライドできるテンプレート変数の作成に使用されます。これらの値はジョブ仕様に配置され、ジョブで使用される画像とGPUリソースを制御する正しいフィールドを変更します。
- Parse configuration ボタンをクリックして
gpusテンプレート変数をカスタマイズし始めます。 - Type を
Integerに設定し、 Default 、 Min 、 Max を選択した値に設定します。このテンプレート変数の制約を違反するrunをこのキューに送信しようとすると、拒否されます。
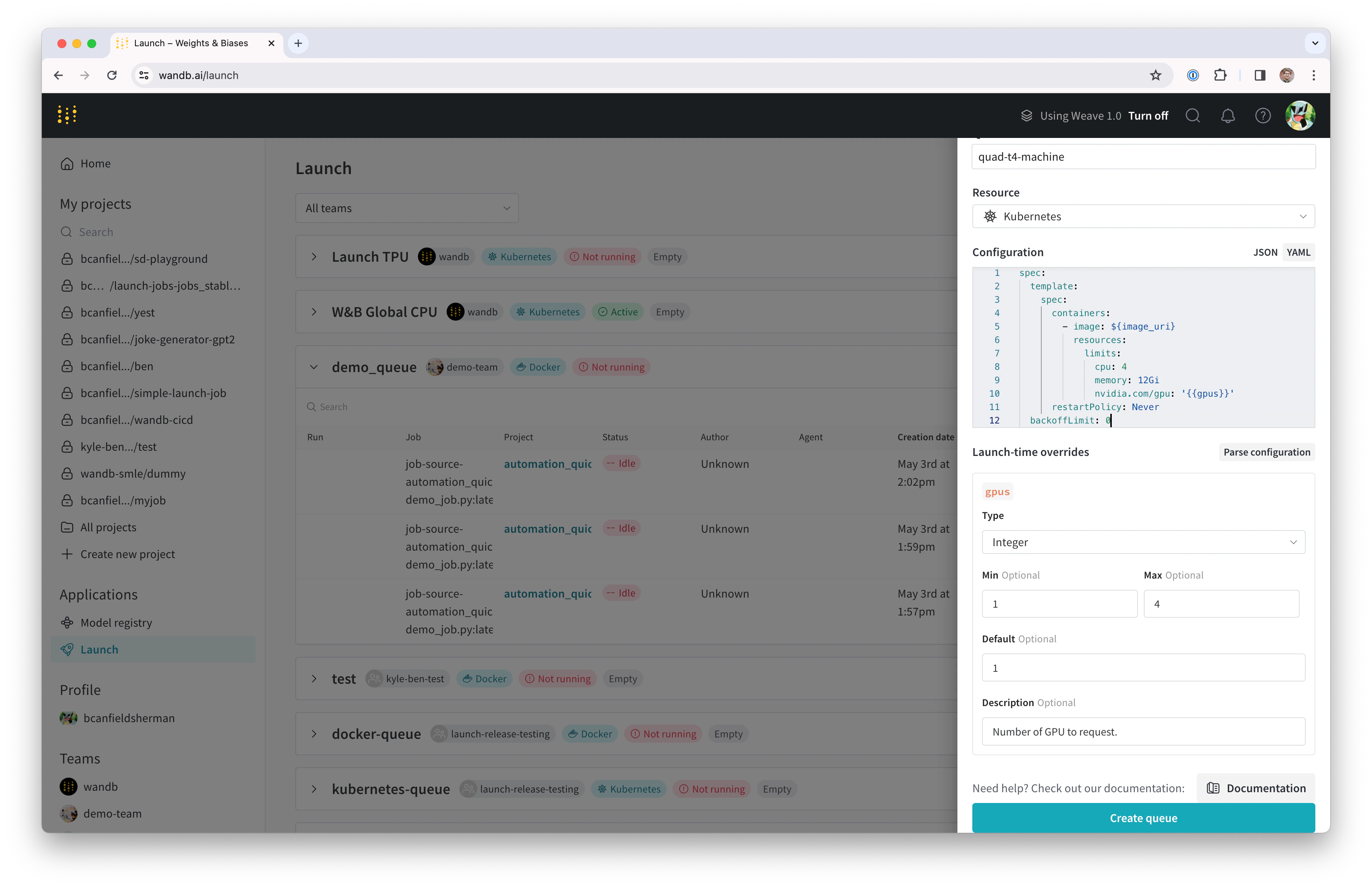
- Create queue をクリックしてキューを作成します。新しいキューのキューページにリダイレクトされます。
Docker + NVIDIA CTKのセットアップ
既にマシンでDockerとNvidiaコンテナツールキットを設定している場合は、このセクションをスキップできます。 Dockerのドキュメントを参照して、システム上でのDockerコンテナエンジンのセットアップ手順を確認してください。 Dockerがインストールされたら、その後にNvidiaコンテナツールキットをNvidiaのドキュメント に従ってインストールします。 コンテナランタイムがGPUにアクセスできることを確認するには、次を実行します:nvidia-smi の出力が表示されるはずです。たとえば、私たちのセットアップでは、出力は次のようになります:
Minikubeの設定
MinikubeのGPUサポートにはバージョンv1.32.0以上が必要です。Minikubeのインストールドキュメント を参照して、最新のインストール方法を確認してください。このチュートリアルでは、次のコマンドを使用して最新のMinikubeリリースをインストールしました:
launch エージェントを開始
新しいクラスター向けのlaunchエージェントは、wandb launch-agentを直接呼び出すか、W&Bによって管理されるHelmチャートを使用してlaunchエージェントをデプロイすることによって開始されます。
このチュートリアルでは、エージェントをホストマシンで直接実行します。
コンテナ外でエージェントを実行することも、ローカルDockerホストを使用してクラスター用の画像を構築できることを意味します。
wandb loginを実行するか、WANDB_API_KEY環境変数を設定します。
エージェントを開始するには、次のコマンドを実行します:
ジョブを起動
エージェントにジョブを送信しましょう。W&Bアカウントにログインしているターミナルから、以下のコマンドで簡単な “hello world” を起動できます:(オプション) NFSを用いたモデルとデータキャッシング
ML ワークロードのために、複数のジョブが同じデータにアクセスできるようにしたい場合があります。たとえば、大規模なアセット(データセットやモデルの重みなど)の再ダウンロードを避けるために共有キャッシュを持つことができます。Kubernetesは、永続ボリュームと永続ボリュームクレームを通じてこれをサポートしています。永続ボリュームは、KubernetesワークロードにおいてvolumeMounts を作成し、共有キャッシュへの直接ファイルシステムアクセスを提供します。
このステップでは、モデルの重みをキャッシュとして共有するために使用できるネットワークファイルシステム(NFS)サーバーをセットアップします。最初のステップはNFSをインストールし、設定することです。このプロセスはオペレーティングシステムによって異なります。私たちのVMはUbuntuを実行しているので、nfs-kernel-serverをインストールし、/srv/nfs/kubedataでエクスポートを設定しました:
nfs-persistent-volume.yaml というファイルにコピーし、希望のボリュームキャパシティとクレームリクエストを記入してください。PersistentVolume.spec.capcity.storage フィールドは、基になるボリュームの最大サイズを制御します。PersistentVolumeClaim.spec.resources.requests.storage は、特定のクレームに割り当てられるボリュームキャパシティを制限するために使用できます。私たちのユースケースでは、それぞれに同じ値を使用するのが理にかなっています。
volumes と volumeMounts を追加する必要があります。launchの設定を編集するには、再び wandb.ai/launch(またはwandbサーバー上のユーザーの場合は<your-wandb-url>/launch)に戻り、キューを見つけ、キューページに移動し、その後、Edit config タブをクリックします。元の設定を次のように変更できます:
- YAML
- JSON
/root/.cache にマウントされます。コンテナが root 以外のユーザーとして実行される場合、マウントパスは調整が必要です。HuggingfaceのライブラリとW&B Artifactsは、デフォルトで $HOME/.cache/ を利用しているため、ダウンロードは一度だけ行われるはずです。
安定拡散と遊ぶ
新しいシステムをテストするために、安定的な拡散の推論パラメータを実験します。 デフォルトのプロンプトと常識的なパラメータでシンプルな安定的拡散推論ジョブを実行するには、次のコマンドを実行します:wandb/job_stable_diffusion_inference:main コンテナイメージを送信します。
エージェントがジョブを受け取り、クラスターで実行するためにスケジュールするとき、接続に依存してイメージがプルされるまで時間がかかることがあります。
ジョブのステータスはwandb.ai/launch(またはwandbサーバー上のユーザーの場合の<your-wandb-url>/launch)キューページで確認できます。
runが終了すると、指定したプロジェクトにジョブアーティファクトがあるはずです。
プロジェクトのジョブページ (<project-url>/jobs) にアクセスしてジョブアーティファクトを見つけることができます。デフォルトの名前は job-wandb_job_stable_diffusion_inference ですが、ジョブのページでジョブ名の横にある鉛筆アイコンをクリックして好きなように変更できます。
このジョブを使って、クラスター上でさらに安定的な拡散推論を実行することができます。
ジョブページから、右上隅にある Launch ボタンをクリックして新しい推論ジョブを設定し、キューに送信します。ジョブの設定ページは、元のrunからのパラメータで自動的に入力されますが、 Overrides セクションで値を変更することで好きなように変更できます。