Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-update-training-api-26.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Hugging Face Diffusers は、画像、オーディオ、さらには分子の3D構造を生成するための最先端の学習済み拡散モデルのためのライブラリです。W&B インテグレーションは、柔軟な実験管理、メディア可視化、パイプライン アーキテクチャー、および設定管理をインタラクティブで集中化されたダッシュボードに追加し、使いやすさを損ないません。
たった2行で次世代のログ
実験に関連するすべてのプロンプト、ネガティブプロンプト、生成されたメディア、および設定を、たった2行のコードを含めるだけでログできます。ログを始めるためのコードはこちらの2行です:
# autolog 関数をインポート
from wandb.integration.diffusers import autolog
# パイプラインを呼び出す前に autolog を呼ぶ
autolog(init=dict(project="diffusers_logging"))
始め方
-
diffusers, transformers, accelerate, および wandb をインストールします。
-
コマンドライン:
pip install --upgrade diffusers transformers accelerate wandb
-
ノートブック:
!pip install --upgrade diffusers transformers accelerate wandb
-
autolog を使用して Weights & Biases の run を初期化し、すべてのサポートされているパイプライン呼び出しからの入出力を自動的に追跡します。
init パラメータを持つ autolog() 関数を呼び出すことができ、このパラメータは wandb.init() によって要求されるパラメータの辞書が受け入れられます。
autolog() を呼び出すと、Weights & Biases の run が初期化され、すべてのサポートされているパイプライン呼び出しからの入力と出力が自動的に追跡されます。
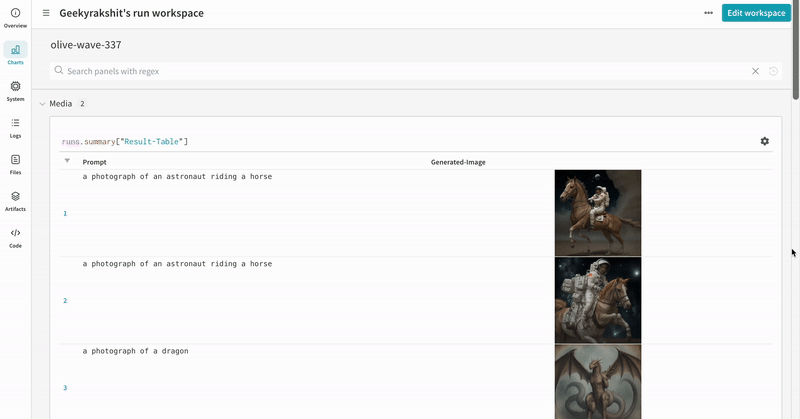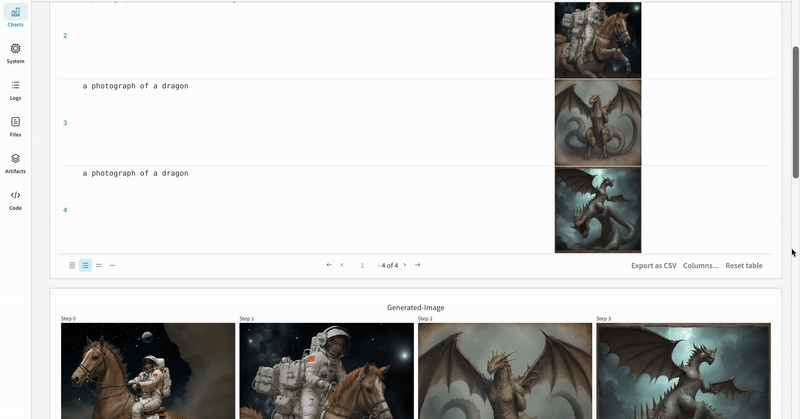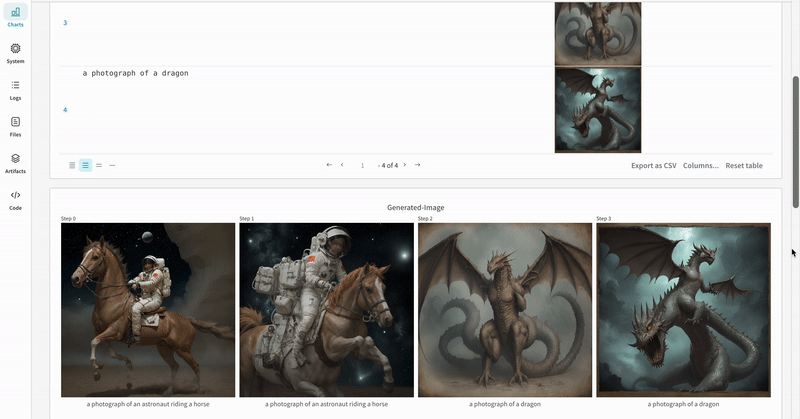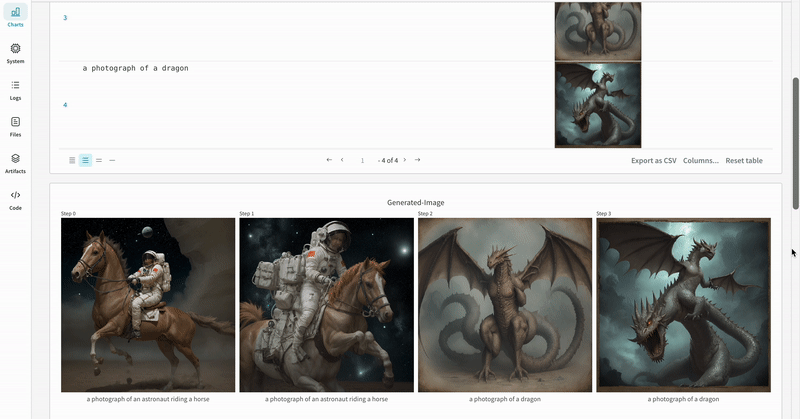
- 各パイプライン呼び出しはその run のワークスペース内の独自の table に追跡され、パイプライン呼び出しに関連する設定はその run のワークフローリストに追加されます。
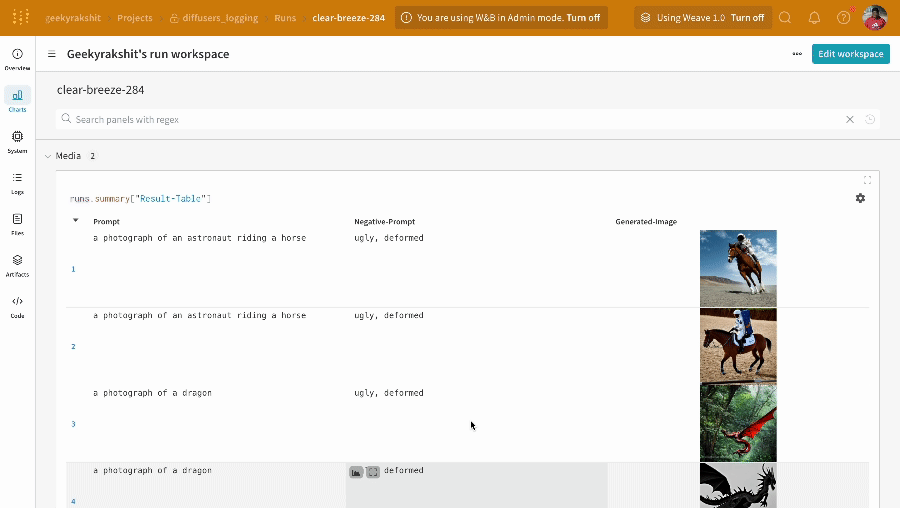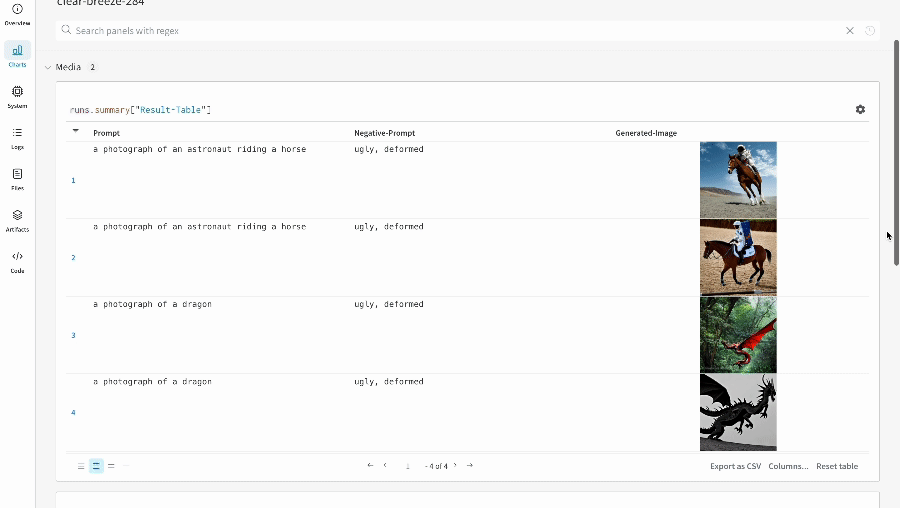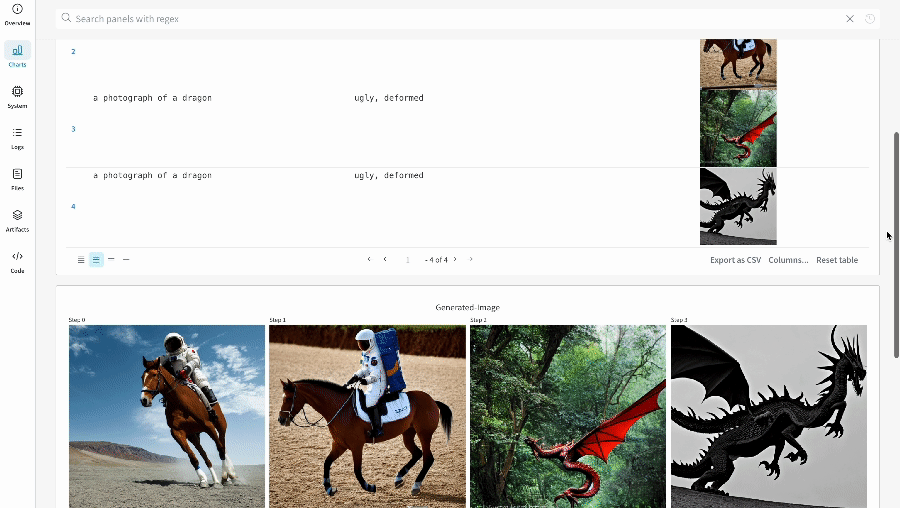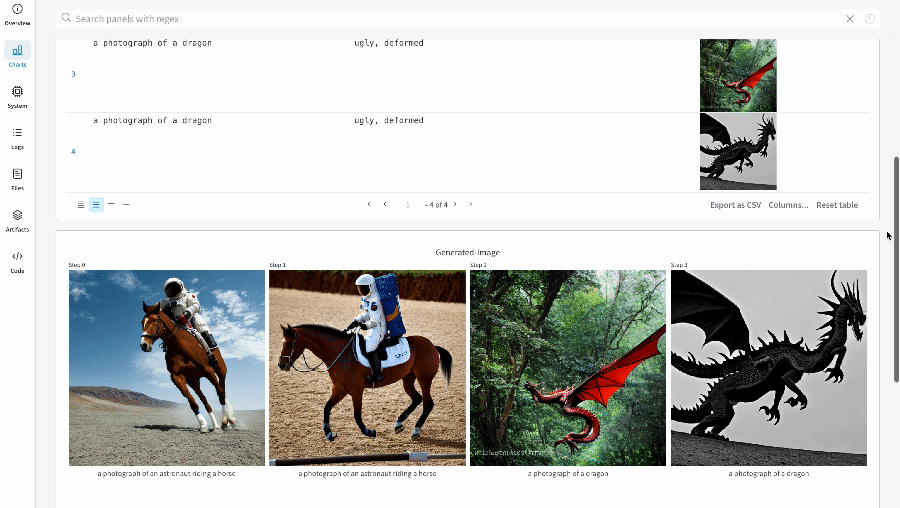
- プロンプト、ネガティブプロンプト、生成されたメディアは
wandb.Table にログされます。
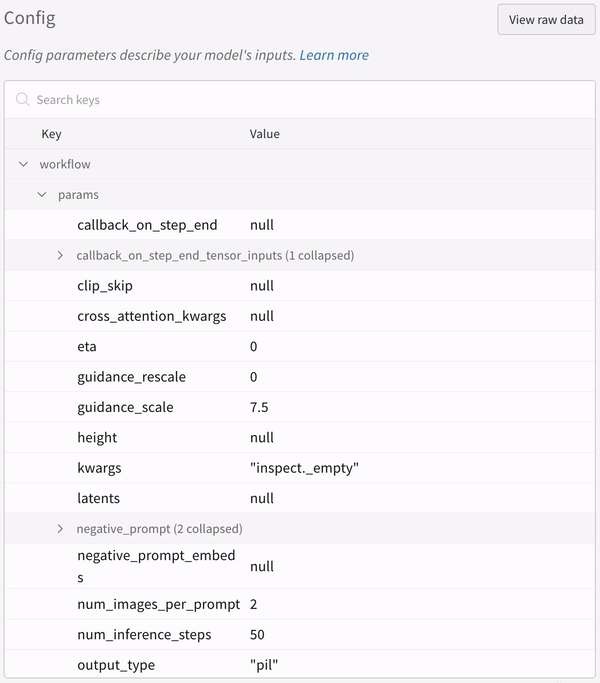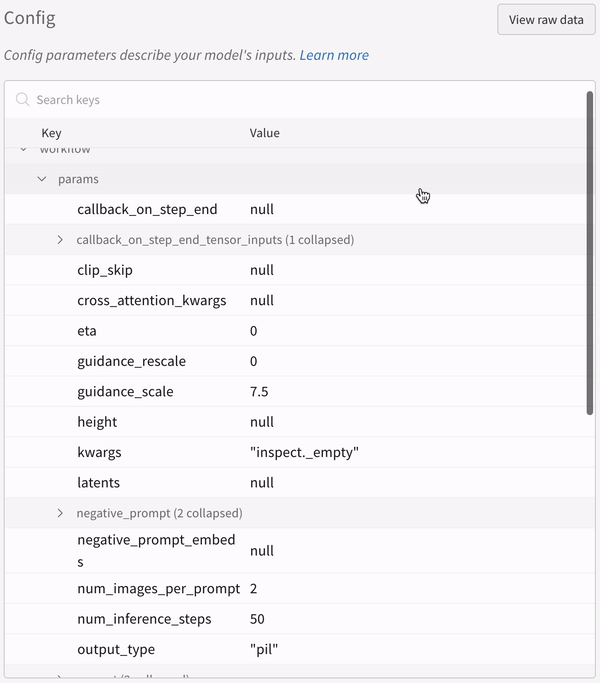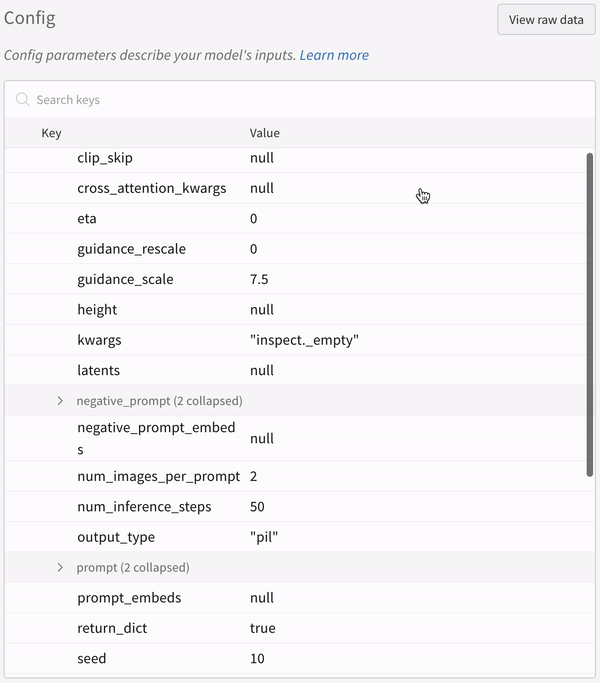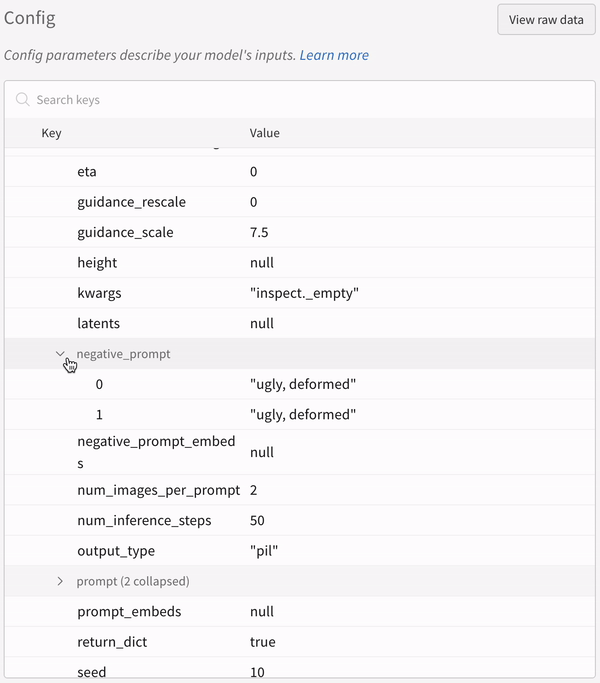
- シードやパイプライン アーキテクチャーを含む実験に関連するすべての他の設定は、その run の設定セクションに保存されます。
- 各パイプライン呼び出しの生成されたメディアは run の media panels にもログされます。
Autologging
ここでは、autolog の動作を示す簡単なエンドツーエンドの例を示します。
import torch
from diffusers import DiffusionPipeline
# autolog 関数をインポート
from wandb.integration.diffusers import autolog
# パイプラインを呼び出す前に autolog を呼ぶ
autolog(init=dict(project="diffusers_logging"))
# 拡散パイプラインを初期化
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
).to("cuda")
# プロンプト、ネガティブプロンプト、種を定義
prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"]
negative_prompt = ["ugly, deformed", "ugly, deformed"]
generator = torch.Generator(device="cpu").manual_seed(10)
# パイプラインを呼び出して画像を生成
images = pipeline(
prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=2,
generator=generator,
)
import torch
from diffusers import DiffusionPipeline
import wandb
# autolog 関数をインポート
from wandb.integration.diffusers import autolog
# パイプラインを呼び出す前に autolog を呼ぶ
autolog(init=dict(project="diffusers_logging"))
# 拡散パイプラインを初期化
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
).to("cuda")
# プロンプト、ネガティブプロンプト、種を定義
prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"]
negative_prompt = ["ugly, deformed", "ugly, deformed"]
generator = torch.Generator(device="cpu").manual_seed(10)
# パイプラインを呼び出して画像を生成
images = pipeline(
prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=2,
generator=generator,
)
# 実験を終了
wandb.finish()
-
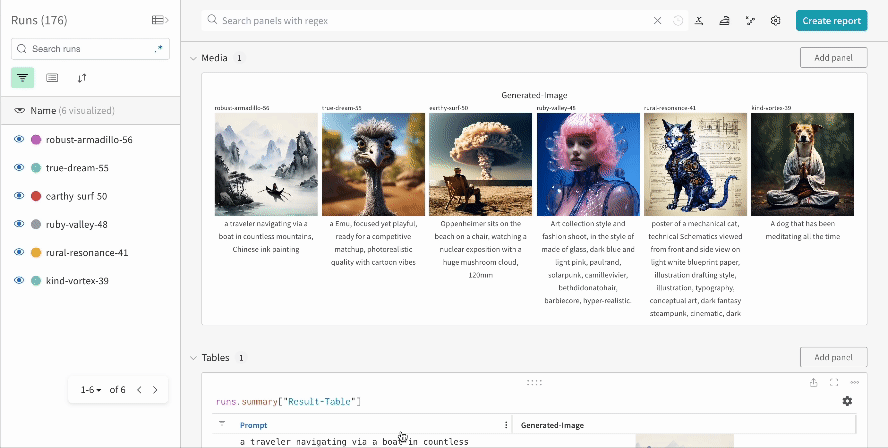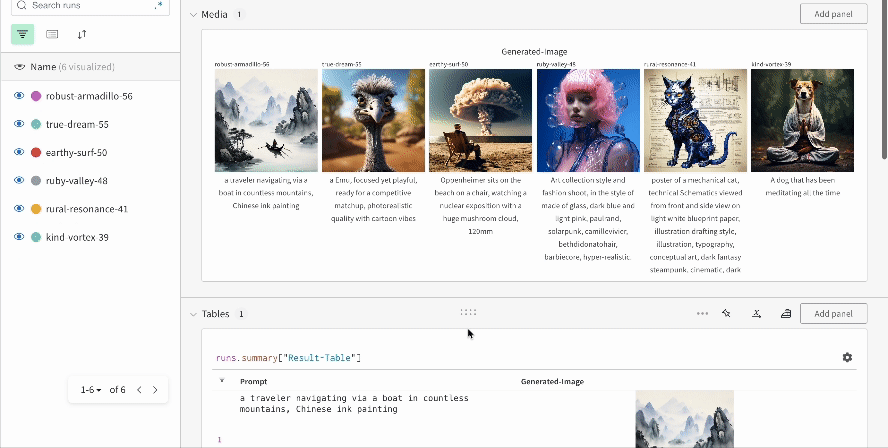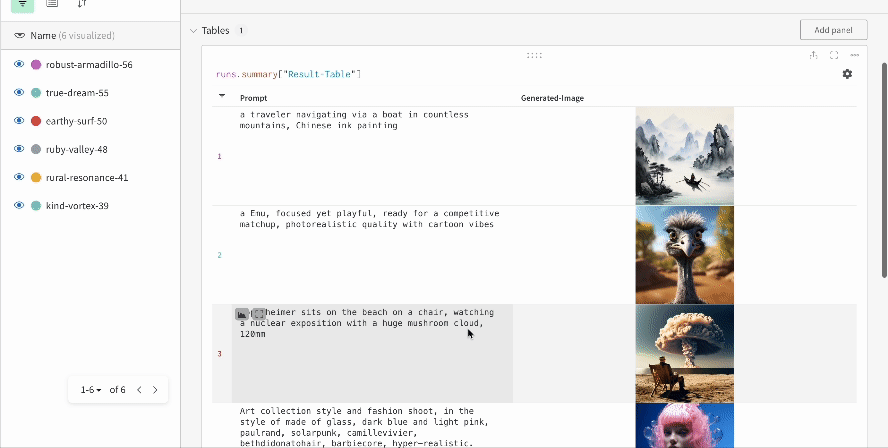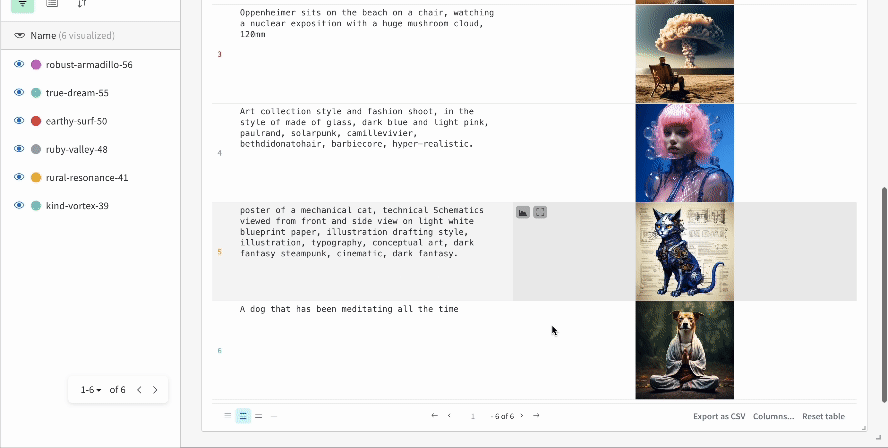
単一の実験の結果:
-
複数の実験の結果:
-
実験の設定:
パイプラインを呼び出した後、IPython ノートブック環境でコードを実行する際には wandb.finish()を明示的に呼び出す必要があります。Python スクリプトを実行する際は必要ありません。 マルチパイプライン ワークフローの追跡
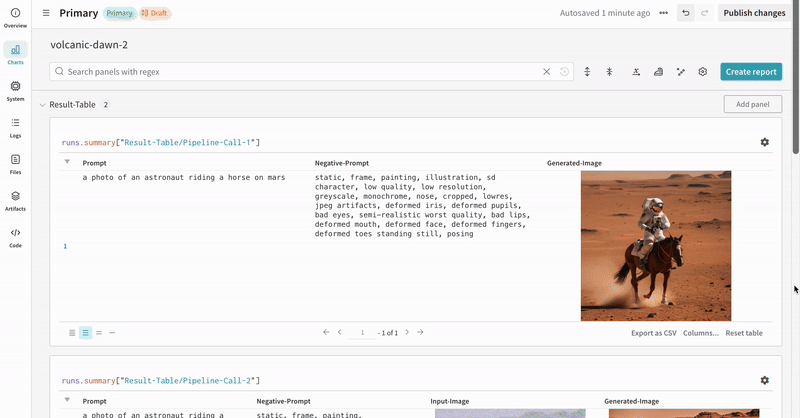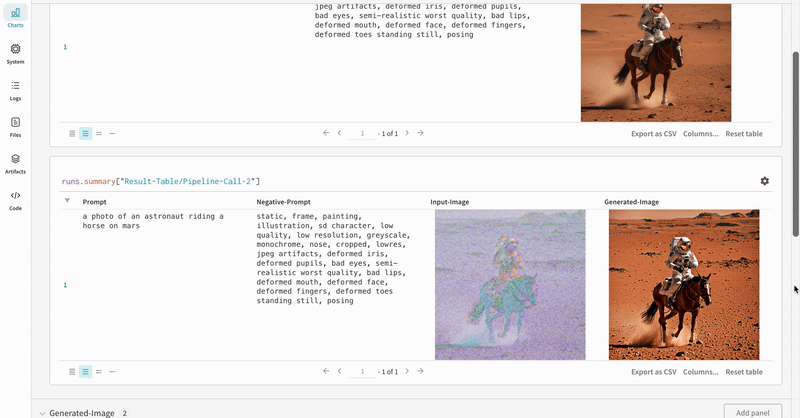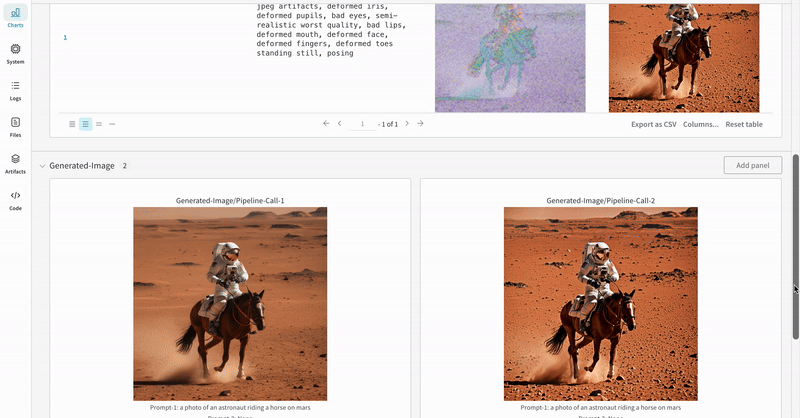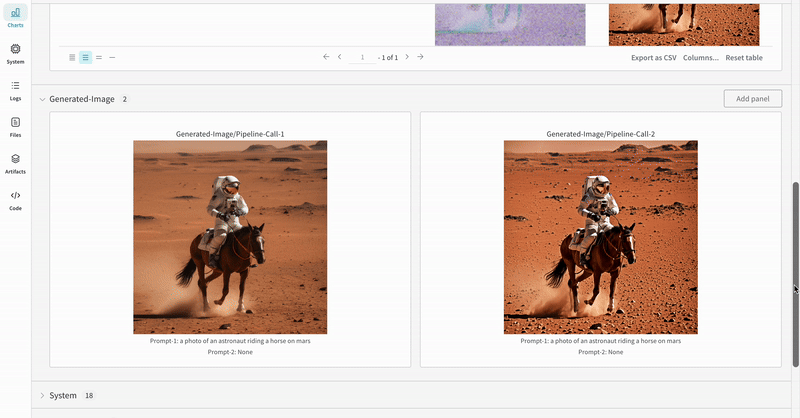
このセクションでは、StableDiffusionXLPipeline で生成された潜在変数が対応するリファイナーによって調整される、典型的なStable Diffusion XL + Refiner ワークフローを使用した autolog のデモンストレーションを行います。
import torch
from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline
from wandb.integration.diffusers import autolog
# SDXL ベース パイプラインを初期化
base_pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True,
)
base_pipeline.enable_model_cpu_offload()
# SDXL リファイナー パイプラインを初期化
refiner_pipeline = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base_pipeline.text_encoder_2,
vae=base_pipeline.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
refiner_pipeline.enable_model_cpu_offload()
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing"
# 乱数を制御することで実験を再現可能にします。
# シードは自動的に WandB にログされます。
seed = 42
generator_base = torch.Generator(device="cuda").manual_seed(seed)
generator_refiner = torch.Generator(device="cuda").manual_seed(seed)
# WandB Autolog を Diffusers に呼び出します。これにより、
# プロンプト、生成された画像、パイプライン アーキテクチャー、すべての
# 関連する実験設定が Weights & Biases に自動的にログされ、
# 画像生成実験を簡単に再現、共有、分析できるようになります。
autolog(init=dict(project="sdxl"))
# ベースパイプラインを呼び出して潜在変数を生成
image = base_pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
output_type="latent",
generator=generator_base,
).images[0]
# リファイナーパイプラインを呼び出して調整された画像を生成
image = refiner_pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
image=image[None, :],
generator=generator_refiner,
).images[0]
import torch
from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline
import wandb
from wandb.integration.diffusers import autolog
# SDXL ベース パイプラインを初期化
base_pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True,
)
base_pipeline.enable_model_cpu_offload()
# SDXL リファイナー パイプラインを初期化
refiner_pipeline = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base_pipeline.text_encoder_2,
vae=base_pipeline.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
refiner_pipeline.enable_model_cpu_offload()
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing"
# 乱数を制御することで実験を再現可能にします。
# シードは自動的に WandB にログされます。
seed = 42
generator_base = torch.Generator(device="cuda").manual_seed(seed)
generator_refiner = torch.Generator(device="cuda").manual_seed(seed)
# WandB Autolog を Diffusers に呼び出します。これにより、
# プロンプト、生成された画像、パイプライン アーキテクチャー、すべての
# 関連する実験設定が Weights & Biases に自動的にログされ、
# 画像生成実験を簡単に再現、共有、分析できるようになります。
autolog(init=dict(project="sdxl"))
# ベースパイプラインを呼び出して潜在変数を生成
image = base_pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
output_type="latent",
generator=generator_base,
).images[0]
# リファイナーパイプラインを呼び出して調整された画像を生成
image = refiner_pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
image=image[None, :],
generator=generator_refiner,
).images[0]
# 実験を終了
wandb.finish()
- Stable Diffusion XL + Refiner の実験の例:
追加リソース